Jag kommer att utföra klassificering med hjälp av neurala nätverk i denna handledning. Jag använder en genererad datauppsättning med spiraler, koden för att generera datauppsättningen ingår i denna handledning. Jag ska träna och utvärdera två neurala nätverksmodeller i Python, en MLP-klassificerare från scikit-learn och en anpassad modell skapad med keras funktionella API.
Ett neuralt nätverk försöker att avbilda en djurhjärna, ett sådant nätverk har sammankopplade noder i tre eller flera lager. Ett neuralt nätverk innehåller vikter, en poängfunktion och en förlustfunktion. Ett neuralt nätverk lär sig i en återkopplingsslinga, nätverket justerar vikterna baserat på resultaten från poängfunktionen och förlustfunktionen. Ett enkelt neuralt nätverk innehåller tre lager, ett lager för indata, ett dolt lager och ett lager för utdata. Om ett neuralt nätverk har fler än 3 lager kallas detta för djupinlärning.

Keras funktionella API kan användas för att bygga väldigt komplexa djupinlärningsmodeller med flera lager, bilden ovan är ett diagram över modellen som används i denna handledning. Jag tar en tvådimensionell lista som indata (x, y), indata-lagret är anslutet till ett dolt lager med 64 noder (du kan testa med fler och färre) och utdata-lagret gör förutsägelser för 3 klasser. Varje klass tilldelas en sannolikhet och jag väljer den klass med högsta sannolikhet som min förutsägelse.
Datauppsättning och bibliotek
Jag genererar en datauppsättning med tre spiraler, detta med hjälp av koden nedan. Datauppsättningen är icke-linjär, en linjär klassificerare har svårt att lära sig utifrån sådana mönster. Jag sparar datauppsättningen i en .csv-fil. Du måste installera Graphviz om du vill avbilda en modell, du måste också lägga till en sökväg till programmets mapp som en miljövariabel. Jag använder följande bibliotek: pandas, joblib, numpy, matplotlib, keras, tensorflow (tensorflow-gpu) och scikit-learn.
import numpy
import pandas
import matplotlib.pyplot as plt
# Generate a data set with spirals
# http://cs231n.github.io/neural-networks-case-study/
def generate_spirals():
N = 400 # number of points per class
D = 2 # dimensionality
K = 3 # number of classes
data = numpy.zeros((N*K,D)) # data matrix (each row = single example)
labels = numpy.zeros(N*K, dtype='uint8') # class labels
for j in range(K):
ix = range(N*j,N*(j+1))
r = numpy.linspace(0.0,1,N) # radius
t = numpy.linspace(j*4,(j+1)*4,N) + numpy.random.randn(N)*0.2 # theta
data[ix] = numpy.c_[r*numpy.sin(t), r*numpy.cos(t)]
labels[ix] = j
# Save to a csv file
f = open('files\\spirals.csv', 'w')
f.write('x,y,label\n')
for i in range(len(labels)):
f.write(str(data[i][0]) + ',' + str(data[i][1]) + ',' + str(labels[i]) + '\n')
f.close()
# Visualize data set
def visualize_data_set():
# Load data set
ds = pandas.read_csv('files\\spirals.csv')
# Print first 5 rows in data set
print('--- First 5 rows ---')
print(ds.head())
# Print the shape
print('\n--- Shape of data set ---')
print(ds.shape)
# Print class distribution
print('\n--- Class distribution ---')
print(ds.groupby('label').size())
# Visualize data set
figure = plt.figure(figsize = (12, 8))
figure.suptitle('Spirals', fontsize=16)
grouped_dataset = ds.groupby('label')
labels = ['0', '1', '2']
for i, group in grouped_dataset:
plt.scatter(group['x'], group['y'], label=labels[int(i)])
plt.ylabel('y')
plt.xlabel('x')
plt.legend()
#plt.show()
plt.savefig('plots\\spirals.png')
# Generate spirals
generate_spirals()
# Visualize data set
visualize_data_set()Visualisera datauppsättning
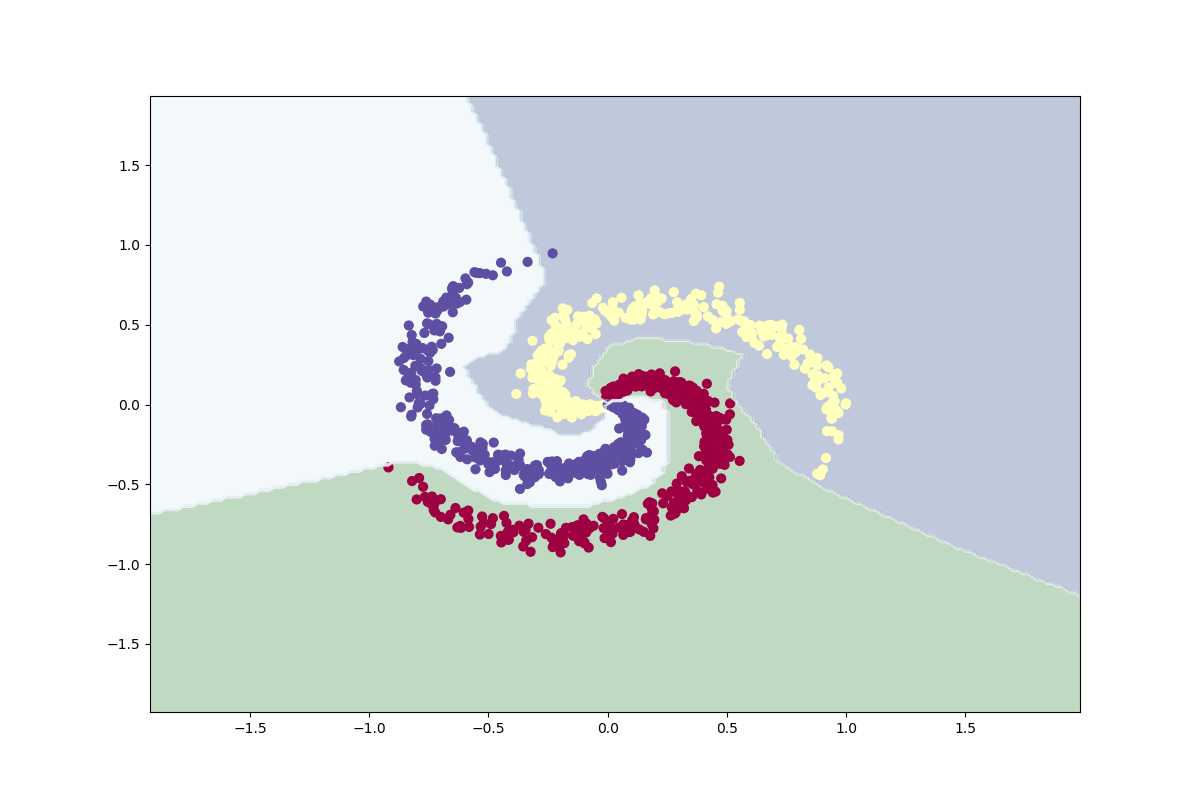
Datauppsättningen är välbalanserad enligt design, den har 1 200 datapunkter och 3 klasser (400 per klass). En linjär klassificering skulle vara mycket dålig avseende denna datauppsättning eftersom det är omöjligt att dela upp datapunkterna med linjer som du kan se på bilden nedan. Det är en sannolikhet om 33,33 % (400/1200) att klassificera en datapunkt korrekt och detta är vår basprestanda, våra modeller måste prestera bättre än detta för att vara användbara.
--- First 5 rows ---
x y label
0 0.000000 0.000000 0
1 -0.000156 0.002501 0
2 -0.001956 0.004615 0
3 0.000877 0.007468 0
4 0.004620 0.008897 0
--- Shape of data set ---
(1200, 3)
--- Class distribution ---
label
0 400
1 400
2 400
dtype: int64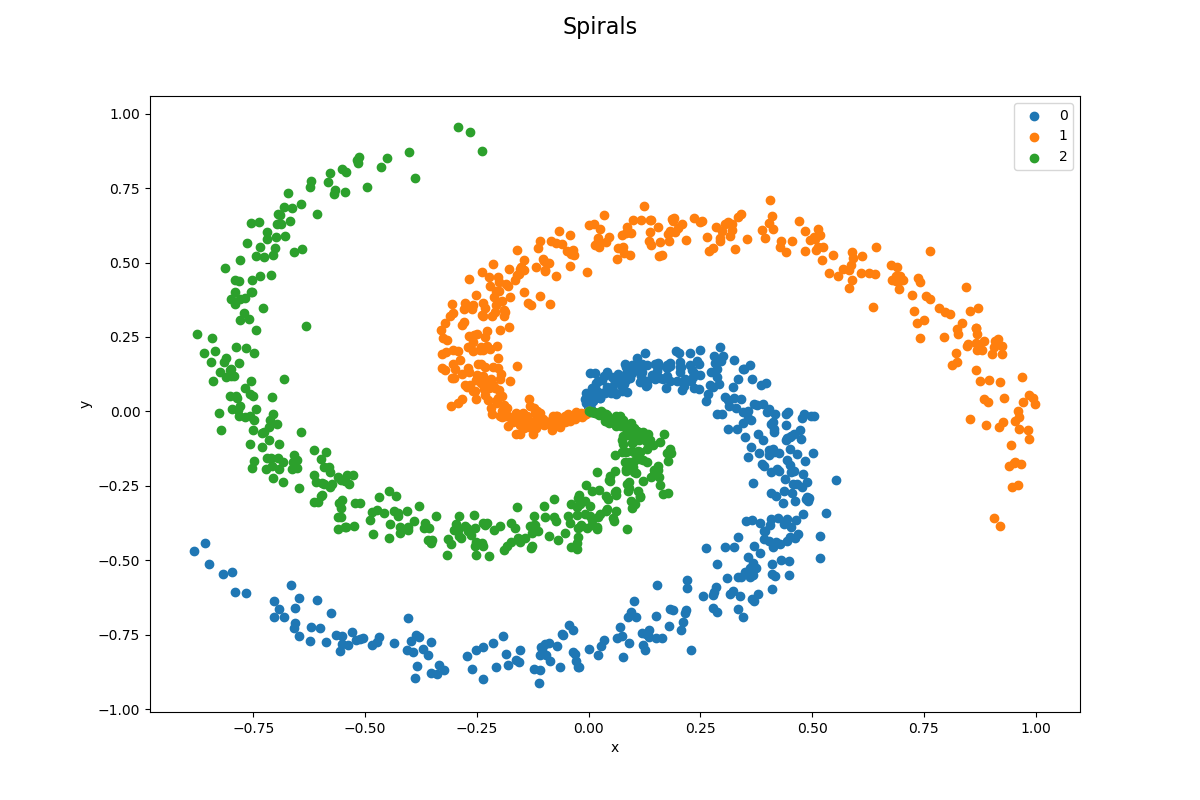
MLP-klassificering
MLP Classifier är en nervnätverksklassificerare i scikit-learn med många hyperparametrar som går att finjustera. Jag använder standardparametrarna när jag tränar min modell. Jag läser in datauppsättningen, delar upp den i data och etiketter, slutligen delas data upp i en träningsuppsättning och en testuppsättning. Jag ser till att uppdelningen blir densamma varje gång genom att använda ett slumpmässigt tillstånd och jag ser till att uppsättningarna är balanserade även efter splittringen. Koden och resultaten från utvärderingsprocessen visas nedan.
# Import libraries
import pandas
import joblib
import numpy as np
import matplotlib.pyplot as plt
import sklearn.model_selection
import sklearn.metrics
import sklearn.neural_network
# Train and evaluate
def train_and_evaluate(X_train, Y_train, X_test, Y_test):
# Create a model
model = sklearn.neural_network.MLPClassifier(hidden_layer_sizes=(100, ), activation='relu', solver='adam',
alpha=0.0001, batch_size='auto', learning_rate='constant', learning_rate_init=0.001, power_t=0.5,
max_iter=1000, shuffle=True, random_state=None, tol=0.0001, verbose=False, warm_start=False, momentum=0.9,
nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08,
n_iter_no_change=10)
# Train the model on the whole data set
model.fit(X_train, Y_train)
# Save the model (Make sure that the folder exists)
joblib.dump(model, 'models\\mlp_classifier.jbl')
# Evaluate on training data
print('\n-- Training data --')
predictions = model.predict(X_train)
accuracy = sklearn.metrics.accuracy_score(Y_train, predictions)
print('Accuracy: {0:.2f}'.format(accuracy * 100.0))
print('Classification Report:')
print(sklearn.metrics.classification_report(Y_train, predictions))
print('Confusion Matrix:')
print(sklearn.metrics.confusion_matrix(Y_train, predictions))
print('')
# Evaluate on test data
print('\n---- Test data ----')
predictions = model.predict(X_test)
accuracy = sklearn.metrics.accuracy_score(Y_test, predictions)
print('Accuracy: {0:.2f}'.format(accuracy * 100.0))
print('Classification Report:')
print(sklearn.metrics.classification_report(Y_test, predictions))
print('Confusion Matrix:')
print(sklearn.metrics.confusion_matrix(Y_test, predictions))
# Plot the classifier
def plot_classifier(X, Y):
# Load the model
model = joblib.load('models\\mlp_classifier.jbl')
# Calculate
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Make predictions
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot diagram
fig = plt.figure(figsize = (12, 8))
plt.contourf(xx, yy, Z, cmap='ocean', alpha=0.25)
plt.contour(xx, yy, Z, colors='w', linewidths=0.4)
plt.scatter(X[:, 0], X[:, 1], c=Y, s=40, cmap='Spectral')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.savefig('plots\\mlp_classifier.png')
# The main entry point for this module
def main():
# Load data set (includes header values)
dataset = pandas.read_csv('files\\spirals.csv')
# Slice data set in data and labels (2D-array)
X = dataset.values[:,0:2] # Data
Y = dataset.values[:,2].astype(int) # Labels
# Split data set in train and test (use random state to get the same split every time, and stratify to keep balance)
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X, Y, test_size=0.2, random_state=5, stratify=Y)
# Make sure that data still is balanced
print('\n--- Class balance ---')
print(np.unique(Y_train, return_counts=True))
print(np.unique(Y_test, return_counts=True))
# Train and evaluate
train_and_evaluate(X_train, Y_train, X_test, Y_test)
# Plot classifier
plot_classifier(X, Y)
# Tell python to run main method
if __name__ == "__main__": main()--- Class balance ---
(array([0, 1, 2]), array([320, 320, 320], dtype=int64))
(array([0, 1, 2]), array([80, 80, 80], dtype=int64))
-- Training data --
Accuracy: 99.38
Classification Report:
precision recall f1-score support
0 1.00 0.98 0.99 320
1 0.99 1.00 0.99 320
2 0.99 1.00 1.00 320
accuracy 0.99 960
macro avg 0.99 0.99 0.99 960
weighted avg 0.99 0.99 0.99 960
Confusion Matrix:
[[315 4 1]
[ 0 319 1]
[ 0 0 320]]
---- Test data ----
Accuracy: 99.17
Classification Report:
precision recall f1-score support
0 1.00 0.99 0.99 80
1 0.98 1.00 0.99 80
2 1.00 0.99 0.99 80
accuracy 0.99 240
macro avg 0.99 0.99 0.99 240
weighted avg 0.99 0.99 0.99 240
Confusion Matrix:
[[79 1 0]
[ 0 80 0]
[ 0 1 79]]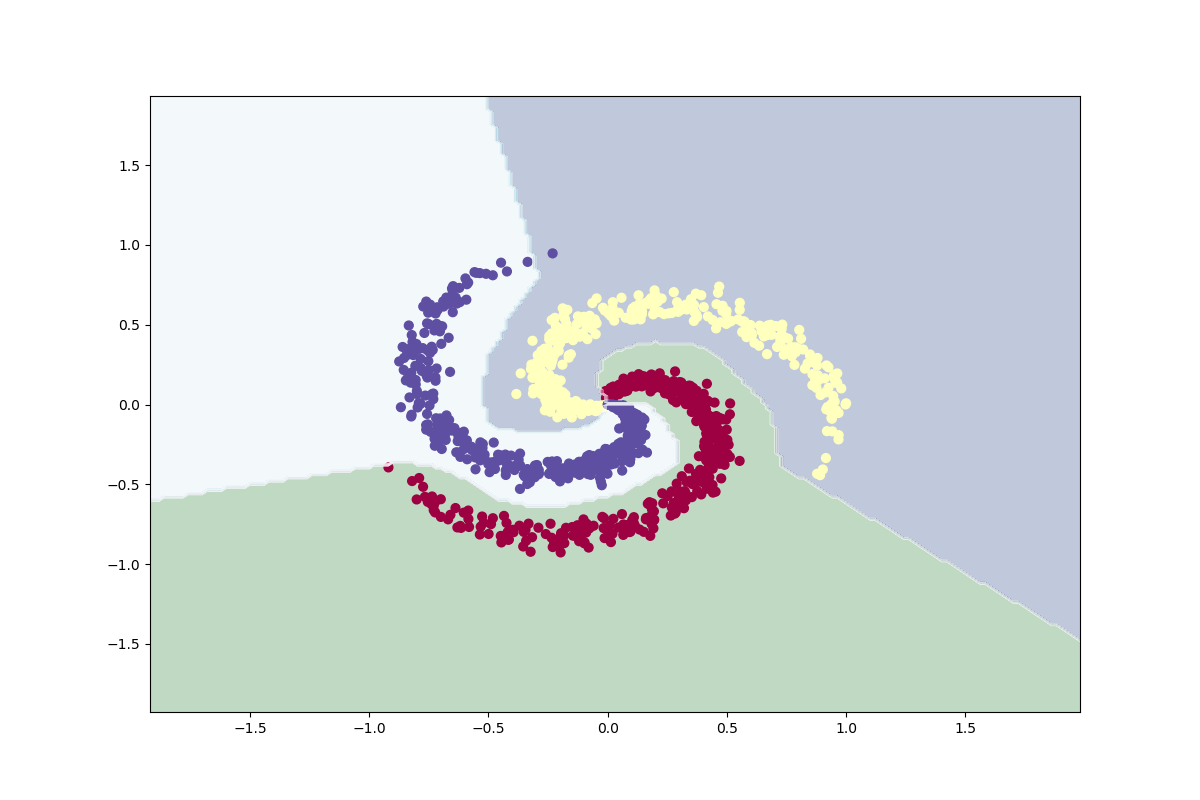
Neural nätverksmodell i keras
Jag läser in och förbereder datauppsättningen på samma sätt som tidigare genom att dela upp den i en träningsuppsättning och en testuppsättning, uppsättningarna är fortfarande balanserade efter delningen. Denna neurala nätverksmodell är byggd med keras funktionella API, den har ett lager för indata, ett dolt lager och ett lager för utdata. Keras funktionella API kan användas för att bygga mycket komplexa djupinlärningsmodeller med många lager. Träningen utvärderas med avseende på noggrannhet och förlustfunktionen är kategorisk korsentropi. Koden och utvärderingsresultaten visas nedan.
# Import libraries
import pandas
import numpy as np
import matplotlib.pyplot as plt
import sklearn.model_selection
import sklearn.metrics
import sklearn.preprocessing
import keras
# Train and evaluate
def train_and_evaluate(X_train, Y_train, X_test, Y_test):
# Create layers (Functional API)
inputs = keras.layers.Input(shape=(2,), dtype='float32', name='input_layer') # Input (2 dimensions)
outputs = keras.layers.Dense(64, activation='relu', name='hidden_layer')(inputs) # Hidden layer
outputs = keras.layers.Dense(3, activation='softmax', name='output_layer')(outputs) # Output layer (3 labels)
# Create a model from input layer and output layers
model = keras.models.Model(inputs=inputs, outputs=outputs, name='neural_network')
# Compile the model (binary_crossentropy if 2 classes)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# Convert labels to categorical: categorical_crossentropy expects targets
# to be binary matrices (1s and 0s) of shape (samples, classes)
Y_binary = keras.utils.to_categorical(Y_train, num_classes=3, dtype='int')
# Train the model on the train set (output debug information)
model.fit(X_train, Y_binary, batch_size=1, epochs=100, verbose=1)
# Save the model (Make sure that the folder exists)
model.save('models\\keras_nn.h5')
# Evaluate on training data
print('\n-- Training data --')
predictions = model.predict(X_train)
accuracy = sklearn.metrics.accuracy_score(Y_train, np.argmax(predictions, axis=1))
print('Accuracy: {0:.2f}'.format(accuracy * 100.0))
print('Classification Report:')
print(sklearn.metrics.classification_report(Y_train, np.argmax(predictions, axis=1)))
print('Confusion Matrix:')
print(sklearn.metrics.confusion_matrix(Y_train, np.argmax(predictions, axis=1)))
print('')
# Evaluate on test data
print('\n---- Test data ----')
predictions = model.predict(X_test)
accuracy = sklearn.metrics.accuracy_score(Y_test, np.argmax(predictions, axis=1))
print('Accuracy: {0:.2f}'.format(accuracy * 100.0))
print('Classification Report:')
print(sklearn.metrics.classification_report(Y_test, np.argmax(predictions, axis=1)))
print('Confusion Matrix:')
print(sklearn.metrics.confusion_matrix(Y_test, np.argmax(predictions, axis=1)))
# Plot the classifier
def plot_classifier(X, Y):
# Load the model
model = keras.models.load_model('models\\keras_nn.h5')
# Plot model (Requires Graphviz)
#keras.utils.plot_model(model, show_shapes=True, rankdir='LR', expand_nested=True, to_file='plots\\keras_nn_model.png')
# Calculate
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Make predictions
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = np.argmax(Z, axis=1)
Z = Z.reshape(xx.shape)
# Plot diagram
fig = plt.figure(figsize = (12, 8))
plt.contourf(xx, yy, Z, cmap='ocean', alpha=0.25)
plt.contour(xx, yy, Z, colors='w', linewidths=0.4)
plt.scatter(X[:, 0], X[:, 1], c=Y, s=40, cmap='Spectral')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.savefig('plots\\keras_nn_classifier.png')
# The main entry point for this module
def main():
# Load data set (includes header values)
dataset = pandas.read_csv('files\\spirals.csv')
# Slice data set in data and labels (2D-array)
X = dataset.values[:,0:2].astype(float) # Data
Y = dataset.values[:,2].astype(int) # Labels
# Split data set in train and test (use random state to get the same split every time, and stratify to keep balance)
X_train, X_test, Y_train, Y_test = sklearn.model_selection.train_test_split(X, Y, test_size=0.2, random_state=5, stratify=Y)
# Make sure that data still is balanced
print('\n--- Class balance ---')
print(np.unique(Y_train, return_counts=True))
print(np.unique(Y_test, return_counts=True))
# Train and evaluate
train_and_evaluate(X_train, Y_train, X_test, Y_test)
# Plot classifier
plot_classifier(X, Y)
# Tell python to run main method
if __name__ == "__main__": main()--- Class balance ---
(array([0, 1, 2]), array([320, 320, 320], dtype=int64))
(array([0, 1, 2]), array([80, 80, 80], dtype=int64))
-- Training data --
Accuracy: 99.69
Classification Report:
precision recall f1-score support
0 1.00 0.99 1.00 320
1 1.00 1.00 1.00 320
2 0.99 1.00 1.00 320
accuracy 1.00 960
macro avg 1.00 1.00 1.00 960
weighted avg 1.00 1.00 1.00 960
Confusion Matrix:
[[318 0 2]
[ 0 319 1]
[ 0 0 320]]
---- Test data ----
Accuracy: 99.58
Classification Report:
precision recall f1-score support
0 1.00 1.00 1.00 80
1 0.99 1.00 0.99 80
2 1.00 0.99 0.99 80
accuracy 1.00 240
macro avg 1.00 1.00 1.00 240
weighted avg 1.00 1.00 1.00 240
Confusion Matrix:
[[80 0 0]
[ 0 80 0]
[ 0 1 79]]